WWDC-Session406-优化App启动时间
理论
Mach-O
Mach-O相关术语
Mach-O为Mach Object文件格式的缩写,它是一种用于可执行文件,目标代码,动态库,内核存储的文件格式。它包括多种文件类型:
Executable(可执行文件):App的主二进制文件Dylib:动态库(如DSO、DLL)Bundle:不能被链接的动态库,只能通过dlopen(),用于Mac OS。
Image:可以是可执行文件、动态库或者bundle。Framework:动态库,包含资源和头文件。
Mach-O Image文件
一个Mach-O文件由3部分组成:Header、Load commands、Raw segment data。Header描述了文件的目标架构等信息,如x86-64,PPC;Load commands列出了文件的逻辑结构及文件在虚拟内存中的布局;Raw segment data包含了在Load commands中指出的segment(段)。在Mach-O文件中,我们把Header、Load commands放在了__TEXT segment(段)的开头,即第一个segment(段)的开头。每一个段由多个page(页)组成,段的大小为页大小的整数倍。如下图,TEXT段占3页,DATA、LINKEDIT分别占1页。页的大小取决于硬件,在arm64下,页大小为16K,其它则为4K。
我们还可以从section(节)的角度来理解段,编译器对section是透明的,section仅仅是一个段的子区间,它没有任何的大小约束,但是section之间不会产生重叠。
事实上,每一个二进制文件都包含TEXT、DATA、LINKEDIT这3个通用的段,TEXT位于文件的开始,它包括Mach header,机器指令,代码以及只读常量如C字符串,DATA段是可读写的,其包括所有的全局变量,静态变量等。LINKEDIT包含加载程序的meta data(元数据),如符号,字符串,重定向表条目,供动态链接器使用。
Mach-O Universal Files
当我们在编译iOS应用时,会针对不同的设备架构编译出不同的Mach-O文件,如下图,产生64位(arm64)、32位(如armv7s)两种架构的Mach-O文件,之后将这两个文件合并成一个文件,这个文件就叫Mach-O universal file。该文件包含一个Fat header,包含所有架构的列表,且对应在文件中的偏移量。header占1页空间,下文,将会讲述为什么需要占1页空间,以及涉及到的虚拟内存的知识。
虚拟内存
每一个进程都是一个逻辑地址空间,逻辑地址会被映射到RAM的物理页中,当然,这个映射并不是一对一的,逻辑地址不需要在一开始就映射到物理内存,多个逻辑地址也可以映射到相同的物理RAM。
如果逻辑地址没有映射到物理RAM,当访问该逻辑地址时,会产生缺页中断,这时,内核会暂停执行该线程,去处理缺页中断;当多个进程,不同的逻辑地址,被映射到相同的物理页时,这些进程就可以共享相同的bit(位),做到进程间共享。
还有一个特点是文件映射,通过mmap函数,可以不用将整个文件加载到RAM中,而把文件的片段映射到进程的内存地址中,所以,在访问未映射的地址时,内核也将产生缺页中断。
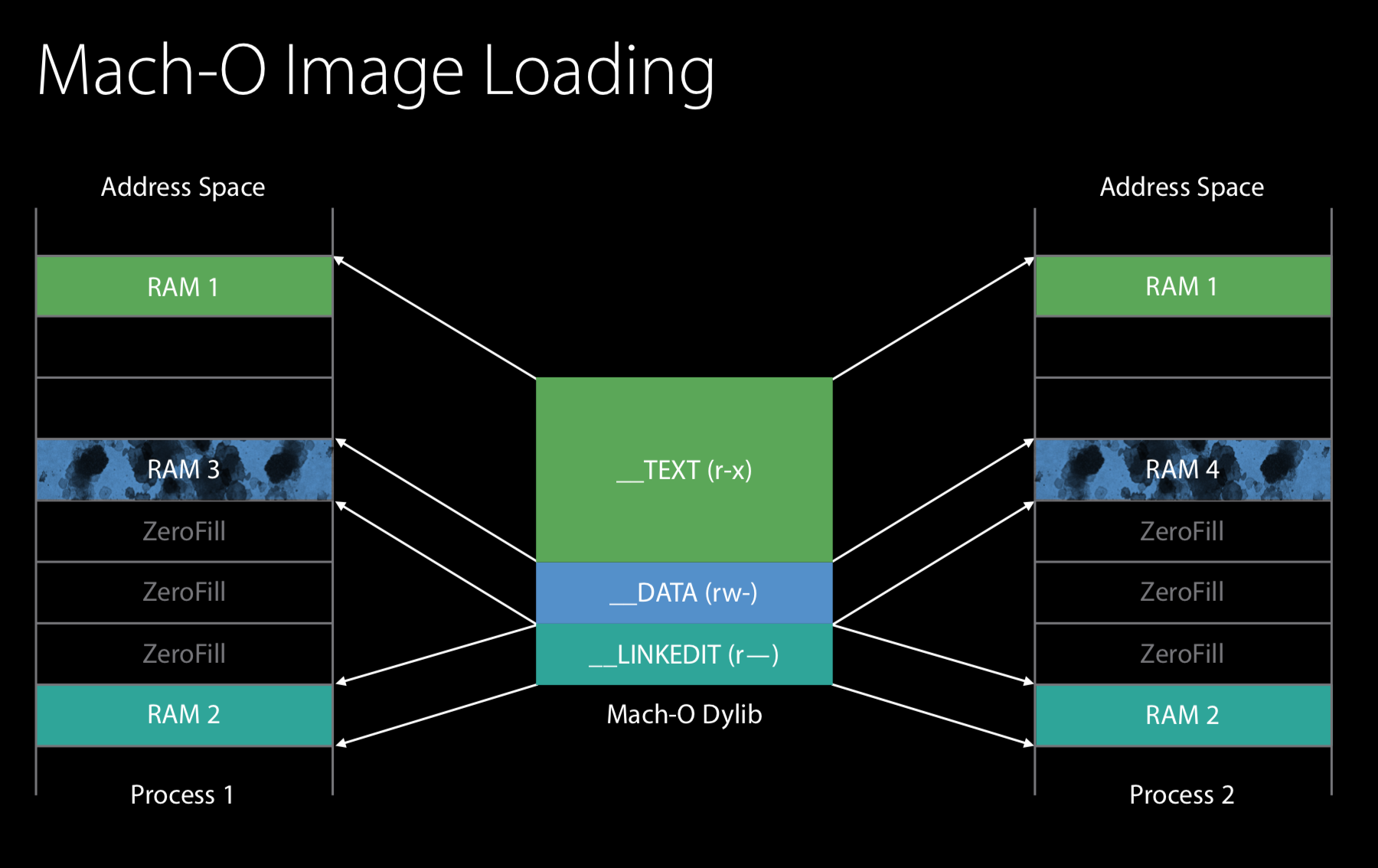
综上,我们可以总结出,动态库或Image的TEXT段可以被映射到多个进程中,其是懒加载的(即使用mmap),共享的。DATA段是可读写的,所以采用了写时复制(COW,Copy-On-Write)的策略,当有进程对DATA进行写时,才真正进行复制的操作,内核会拷贝被修改页到另一个物理RAM并将映射重定向该位置,这时,该进程就拥有了该页的拷贝,该拷贝页被称为dirty page,dirty page包含了进程的特定信息;内核可以重新生成的page称为clean page,当需要访问该页时,可以从磁盘重新读出,显然dirty page代价比clean page大。
接下来,将举一个例子来讲述一下Mach-O和虚拟内存之间的映射。如示例,有一个Mach-O文件,我们将其映射到内存中,而不是将其全部读入内存,如果全部读入内存,需占用8页,而使用映射,其中的ZeroFill将不需要占用空间,原因是大多数的全局变量初始化为0,所以可以对此进行优化,将所有为零的全局变量移到末尾,且不占用磁盘空间,当第一次访问ZeroFill页时,直接赋空,所以,其并不需要进行读操作。dyld一开始会读Mach header,由于其没有映射到物理页,内核将产生缺页中断,VM会读取文件的Mach-O文件的第一页到物理页中,并设置映射,这时,dyld就能开始读取Mach header,读取完Mach header后,Mach header会声称有一些信息保存在LINKEDIT中,需要读取,这时,dyld会跳到Process 1的空间底部,进行LINKEDIT的读取,此时,由于内存中没有,内核会进行和之前读取Mach header时一样的操作,产生缺页中断,读取到物理内存并完成映射,处理完LINKEDIT后,LINKEDIT会告诉dyld,其需要对DATA页进行fix-up(调整)以便让该动态库可运行,此时,内核又会进行之前的操作,不过这次有一些不同,因为该动态库会对DATA进行修改,所以,此时会进行写时复制的操作,该页将变为dirty page,此时,内存中就存在两页clean page和一页dirty page。
此时,如果又有Process 2加载相同的动态库,此时,在Process 2进程中,dyld也会进行相同的步骤。
首先,它会进行Mach header的读取,由于该页已经在RAM中了,所以内核只是简单的将其映射重定向到该页,不需要进行IO,LINKEDIT的读取也是如此,此时到了DATA页,内核会查询RAM中是否存在该DATA页,且是clean page,如果找到,则重用,否则,重新进行读取操作,在该例中,DATA页是dirty page,所以需要再申请一个新的物理页来进行映射,Process 2需修改DATA页,所以DATA页同样标识为dirty page。
最后,由于LINKEDIT页只有在dyld进行处理时需要,所以,一旦dyld完成处理,这些LINKEDIT页占用的空间就可以被收回。这样,这个例子,最终我们仅仅拥有2个dirty page,1个clean,共享的page(LINKEDIT页空间被收回)。
exec()函数 - [main()被调用之前做了什么]
exec是一个系统调用,内核会清理地址空间,将需要运行的可执行文件映射到空间中,且是一个随机地址,接下来,从该地址到0x000000,将被标记为不可读、写和可执行,该区域的大小将不小于4KB(对于32位进程)或4GB(对于64位进程)。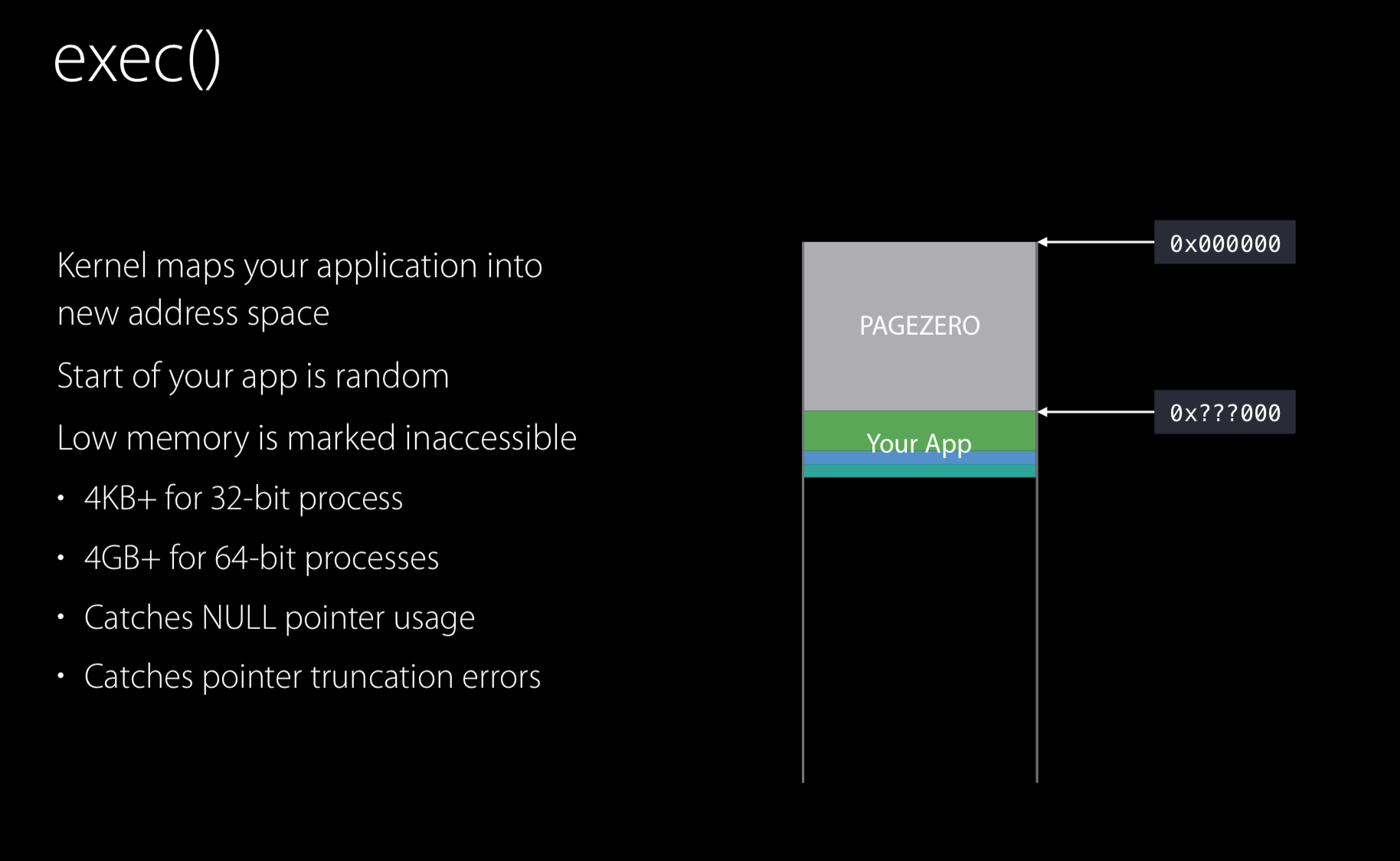
现代程序中,我们经常会使用共享库,如Unix中so,所以,当内核完成进程的映射后,将会把dyld映射到另一个随机的地址,并让dyld来完成进程的启动。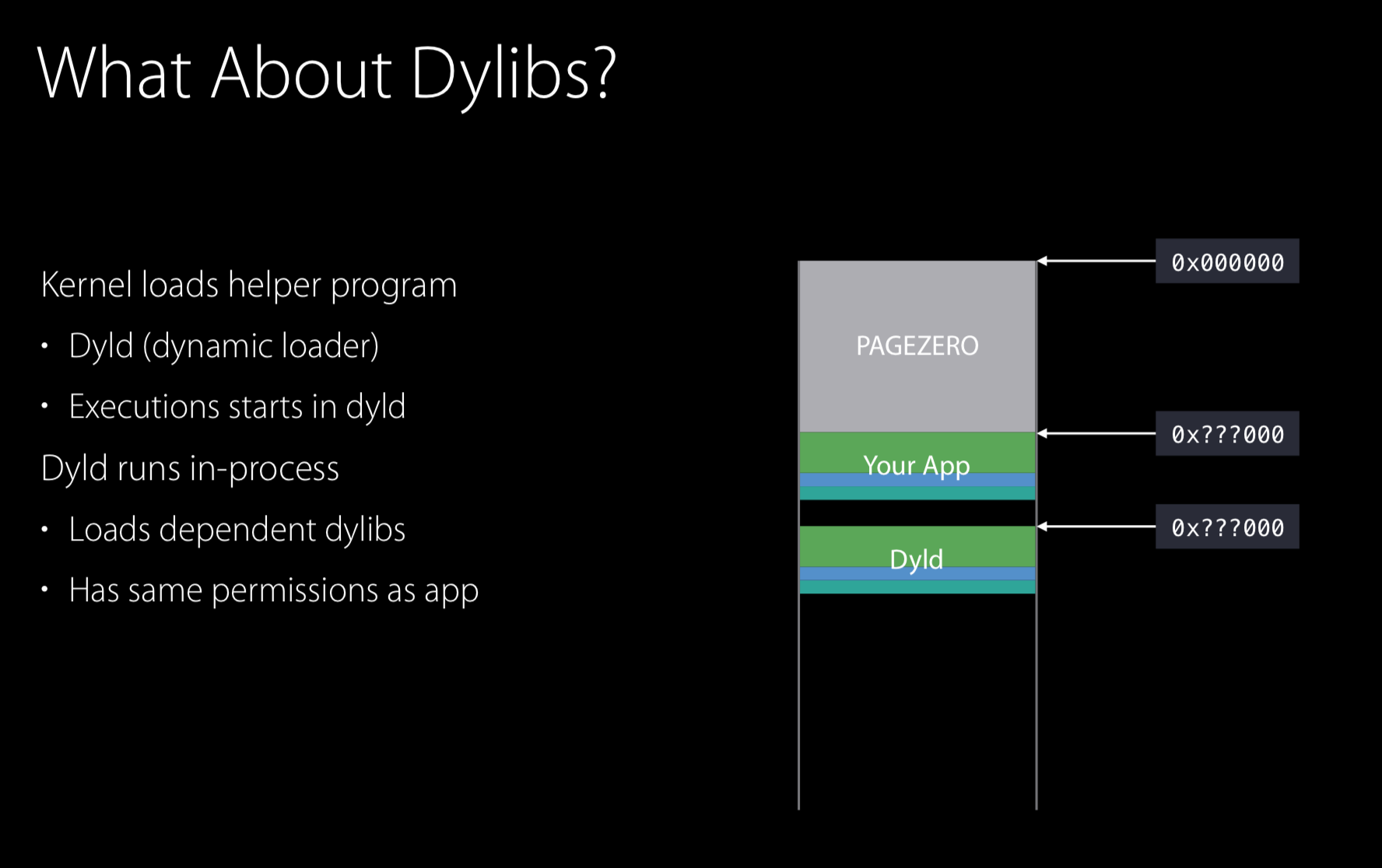
此时,dyld运行在进程中,并负责加载依赖的所有动态库,准备好并运行。
在整个dyld处理的过程中,需要如下图所示的几步,首先,dyld加载所有依赖的动态库(通过读取主可执行文件的header来获得依赖库列表),在加载时,存在某个动态库依赖其他动态库的情况,这个过程是递归执行的。通常,进程会加载100到400个动态库,不过我们几乎不用考虑性能的问题,因为这些库很多都是系统库,内核已经提前加载缓存了。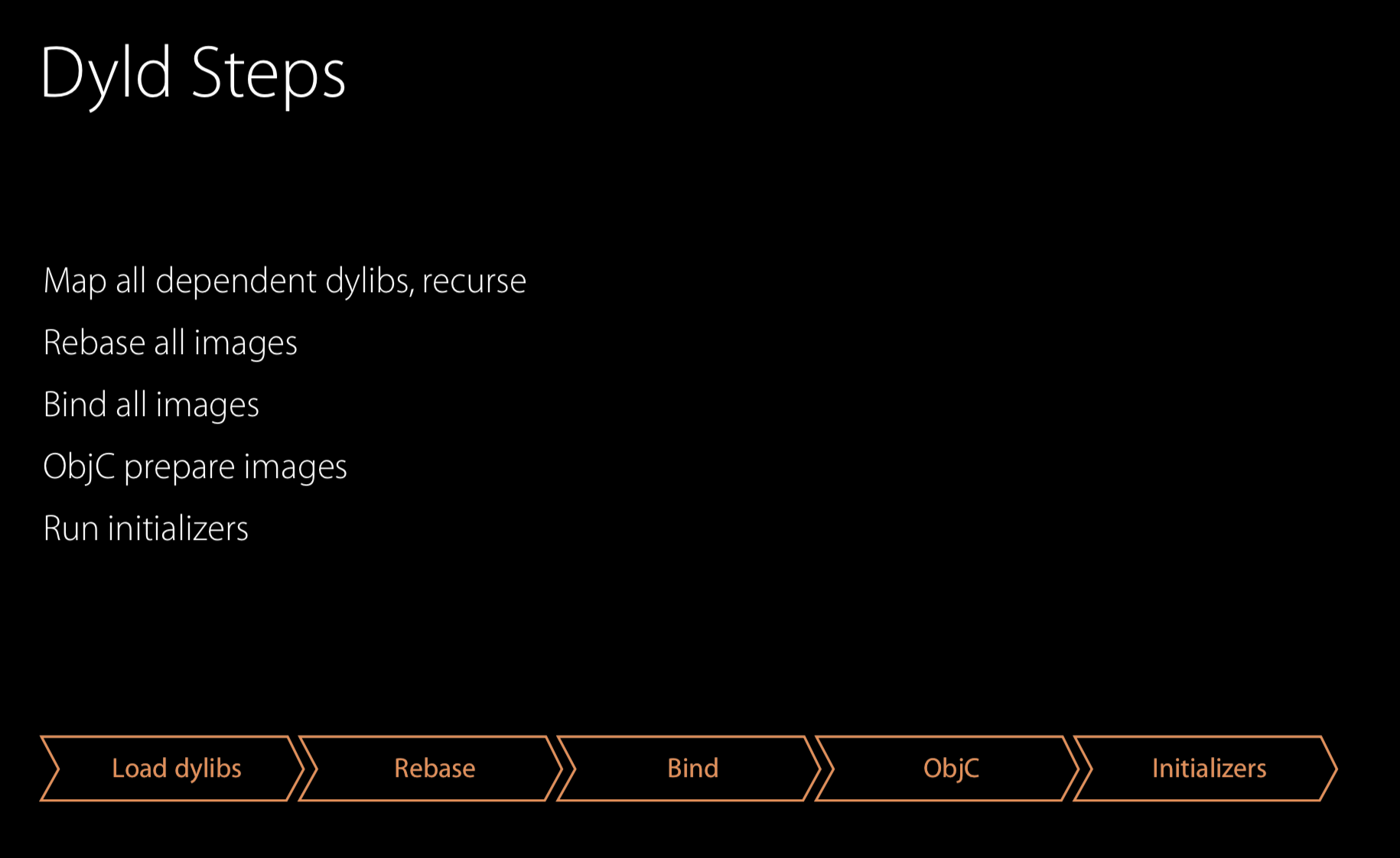
接下来是rebasing和binding,两者的区别为rebasing是当指针指向自己的image而做出调整(调整起来很简单,加一个offset就可以),binding是指针指向其他的image而做出调整。调整都是在DATA页中进行。
有人会问,为什么会需要进行调整呢,主要考虑的因素是安全,不能直接修改指令,所以当一个动态库需要调用其它的动态库时,需要在其中加一个间接层,在DATA段中来创建一个指针指向调用的地址,这就涉及到指针的调整,dyld就负责这些操作。
Objective-C的类结构指针、方法指针等,也都是通过rebasing或binding来进行调整,由于Objective-C是动态语言,我们可以通过字符串来创建一个类实例,所以Objective-C Runtime需要维护一个包括所有类名的映射。
使用过C++的开发者应该知道,C++存在Fragile基类的问题,Objective-C则没有这个问题,因为在加载时,dyld会动态调整所有实例变量的偏移。
处理完前面的操作,如果有C++,这个时候dyld会调用初始化器;如果有Objective-C,类别会被添加到方法列表中,且会调用+load方法,当然,我们已经不推荐使用它了,而是使用+initialize方法。
最终,我们才调用main()。
将理论应用到实际
- 通过设置环境变量
DYLD_PRINT_STATISTICS,可以打印出dyld加载相关信息,包括每部分消耗的时间。 - 前面提到,app平均会有100到400个动态库,但是很多库,系统都已经加载了,但是,有些动态库是无法被系统提前加载的,就是我们内嵌在app中的动态库,所以,加载这些动态库时会带来一些消耗,想要解决这个问题,我们可以将多个动态库合并,可以使用使用静态库;还可以使用延迟加载,既通过
dlopen,不过需要注意的是,dlopen会带来性能和正确性问题,因为它虽然做到了延迟,但是之后需要更多的操作。 - 减少Objective-C类对象和实例变量的数量,因为,如之前所说,数量太多,会增加
rebasing或binding的时间。 - 减少C++虚函数的使用,因为虚函数会创建虚表,其需要在
DATA中创建结构且需要进行调整。 - 使用Swift,Swift做了很多优化,避免了很多操作。
- 推荐用
+initialize来替换+load。 - 不要在初始化器中起线程。
Xcode9后,可以通过Instruments来跟踪静态初始化器的时间。